Tablas Hash, Pilas y Colas: Estructuras de Datos de Alto Rendimiento
- Dacadev
- Programación
- 19 de mayo de 2026
Tabla de Contenido
Hasta ahora hemos visto estructuras secuenciales como los Arrays, donde buscar un elemento requiere revisar celda por celda O(N) o usar búsqueda binaria O(log N) si están ordenados. Pero, ¿qué pasaría si te dijera que existe una estructura capaz de buscar, insertar y borrar datos en un solo paso O(1)?
Hoy explicaremos las Tablas Hash (Hash Tables),las Pilas (Stacks) y las Colas (Queues).
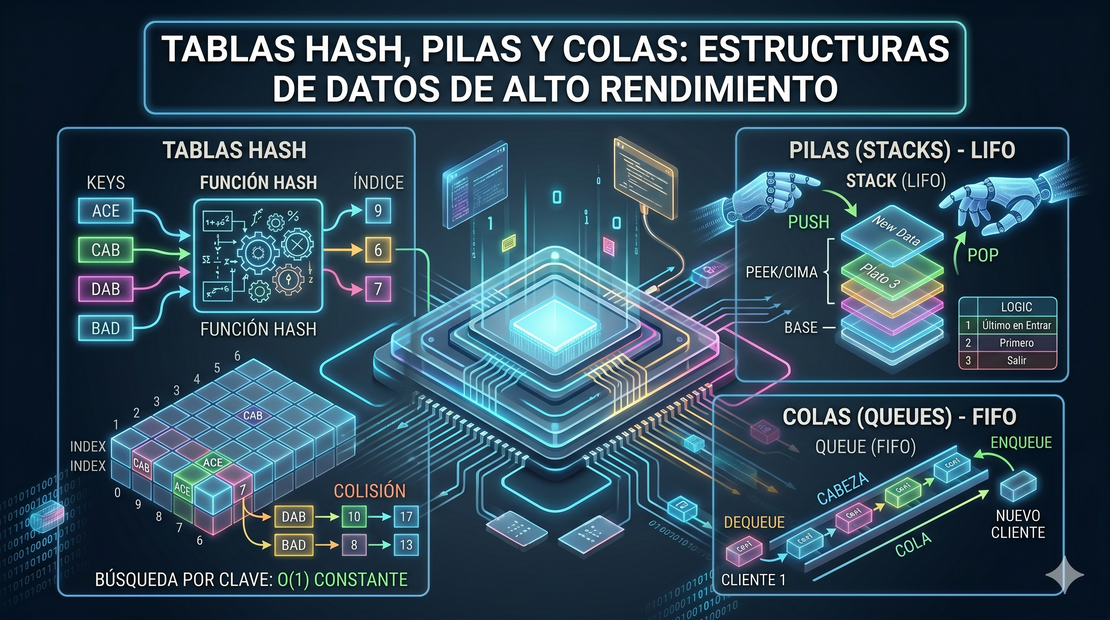
1. ¿Qué es una Tabla Hash (Hash Table)?
Una Tabla Hash (conocida en Python como diccionario, en JavaScript como objeto o Map, y en Go como map) es una estructura que asocia claves (keys) con valores (values).
A diferencia de los Arrays, donde los elementos están ordenados por índices numéricos continuos, las Tablas Hash son estructuras no ordenadas. Su velocidad absurda radica en su proceso interno: el Hashing.
¿Cómo funciona el Hashing?
Cuando guardamos un dato en una Tabla Hash (por ejemplo, {"cab" => "taxi"}), la computadora no busca una celda libre al azar. Utiliza una función hash (hash function) para convertir la clave de texto en un índice numérico específico.
Supongamos que inventamos una función hash súper simple que suma el valor alfabético de las letras de la clave:
- A = 1, B = 2, C = 3, D = 4, E = 5
Si guardamos la clave "ACE":
- A(1) + C(3) + E(5) = 9. El valor se almacena en el índice 9 de nuestra memoria física.
Si guardamos "CAB":
- C(3) + A(1) + B(2) = 6. El valor se almacena en el índice 6.
flowchart LR
Key["Clave: 'ACE'"] --> HashFunc["Función Hash
(Suma de letras)"]
HashFunc --> Index["Índice: 9"]
Index --> Memory["[Celda 9] = 'star'"]
Cuando quieres buscar el valor asociado a "ACE", la computadora no recorre toda la tabla. Simplemente calcula de nuevo Hash("ACE") = 9 y accede de forma instantánea al índice 9 en 1 paso (O(1)). ¡Es brillante!
Colisiones y Load Factor
¿Qué pasa si intentamos insertar "DAB" en nuestro ejemplo anterior?
- D(4) + A(1) + B(2) = 7
¿Y si intentamos insertar
"BAD"? - B(2) + A(1) + D(4) = 7
Ambas claves dan el mismo índice, a esto se le conoce como Colisión Hash. Cuando esto ocurre, la celda 7 debe almacenar una sub-lista de valores, lo que degrada el rendimiento de la búsqueda.
Para evitar colisiones en la vida real, las funciones hash usan matemáticas complejas y se rigen por la regla del Factor de Carga (Load Factor):
- La proporción ideal es tener 10 celdas de memoria por cada 7 elementos almacenados (un factor de carga de 0.7). Esto mantiene un equilibrio perfecto entre uso de memoria y prevención de colisiones.
Eficiencia de las Operaciones en una Hash Table
| Operación | Por Clave (Key) | Por Valor (Value) |
|---|---|---|
| Búsqueda | O(1) (Constante) | O(N) (Lineal) |
| Inserción | O(1) (Constante) | - |
| Eliminación | O(1) (Constante) | - |
Note
La búsqueda de O(1) solo funciona en una dirección: desde la clave al valor. Si necesitas buscar una clave a partir de su valor, la computadora obligatoriamente deberá recorrer toda la estructura de forma lineal (O(N)).
Ejemplo Práctico: Optimizando código con Tablas Hash
Imagina que debes escribir una función en TypeScript que determine si un arreglo es un subconjunto de otro (es decir, si todos los elementos de un arreglo array2 existen en array1).
La versión lenta (O(N \cdot M)) - Bucles anidados:
function isSubsetSlow<T>(arr1: T[], arr2: T[]): boolean {
// Compara cada elemento del segundo arreglo contra todos los del primero
for (const val2 of arr2) {
let found: boolean = false;
for (const val1 of arr1) {
if (val2 === val1) {
found = true;
break;
}
}
if (!found) return false;
}
return true;
}
La versión veloz (O(N + M)) - Usando una Tabla Hash:
function isSubsetFast<T extends PropertyKey>(arr1: T[], arr2: T[]): boolean {
const hashTable: Record<T, boolean> = {} as Record<T, boolean>;
// Guardamos todos los elementos de arr1 en la tabla hash en O(N)
for (const value of arr1) {
hashTable[value] = true;
}
// Comprobamos la existencia de arr2 en O(M)
for (const value of arr2) {
if (!hashTable[value]) {
return false;
}
}
return true;
}
Al transformar la búsqueda lineal anidada en una búsqueda instantánea en una Tabla Hash, convertimos un algoritmo pesado de complejidad multiplicativa a uno de complejidad sumatoria. ¡Es la diferencia entre que un proceso tarde horas o milisegundos!
Pilas (Stacks)
Las Pilas (Stacks) son una estructura de datos abstracta y altamente restrictiva. A diferencia de un Array normal donde puedes leer o insertar en cualquier parte, en un Stack las reglas son estrictas.
Se rigen bajo el principio LIFO (Last In, First Out): el último elemento en entrar es el primero en salir. Imagínalo como una pila de platos en un restaurante, solo puedes interactuar con el plato de arriba.
flowchart TD
subgraph Pila Stack - LIFO
direction TB
E3["[Plato 3] <-- Cima (Peek/Pop)"]
E2["[Plato 2]"]
E1["[Plato 1] <-- Base"]
end
Sus 3 Reglas de Oro:
- Los datos solo se pueden insertar al final (Push).
- Los datos solo se pueden eliminar del final (Pop).
- Solo se puede leer el último elemento (Peek o Cima).
¿Por qué usar una estructura tan restrictiva? Porque nos da seguridad. Al restringir las operaciones de acceso, garantizamos que nadie pueda corromper el orden de los datos intermedios. Es el motor detrás del botón “Deshacer” (Ctrl+Z) de tu editor de texto y del Call Stack de tu procesador.
Colas (Queues)
Las Colas (Queues) son la contraparte directa del Stack. Representan fielmente la fila de un banco o supermercado.
Se rigen por el principio FIFO (First In, First Out): el primer elemento en llegar es el primero en ser atendido.
flowchart LR
subgraph Cola Queue - FIFO
direction LR
S1["[Cliente 1] En cabeza (Atender/Dequeue)"] --> S2["[Cliente 2]"] --> S3["[Cliente 3] En cola (Llegada/Enqueue)"]
end
Sus 3 Reglas de Oro:
- Los datos solo se insertan al final (Enqueue).
- Los datos solo se eliminan del inicio (Dequeue).
- Solo se puede leer el elemento del inicio.
Casos de uso comunes:
- Colas de impresión: los documentos se imprimen exactamente en el orden en que fueron enviados.
- Gestión de tareas asíncronas en servidores web (Message Queues).
- Procesos de background en sistemas operativos.