Estructuras de Datos y Algoritmos: Los Fundamentos que Todo Dev Debe Saber
- Dacadev
- Programación
- 17 de mayo de 2026
Tabla de Contenido
Si estás dando tus primeros pasos en el desarrollo de software, es muy común que midas el éxito de tu código con una única pregunta: ¿funciona y hace lo que se supone que debe hacer?
Sin embargo, a medida que avanzas en tu carrera, te das cuenta de que existe un mundo entero de otras métricas críticas, como por ejemplo: ¿Qué tan rápido se ejecuta? ¿Cuánta memoria consume? ¿Es escalable si el volumen de datos crece por mil?
Para escribir código que no solo funcione sino que sea verdaderamente profesional, debes dominar dos pilares fundamentales: las estructuras de datos y los algoritmos. Empecemos por lo básico: ¿qué son y por qué importan?
¿Por qué importa la estructura?
Consideremos una tarea sencilla: escribir una función en Python que imprima todos los números pares del 2 al 100.
Aquí tienes la versión uno (menos eficiente):
def print_numbers_version_one():
number = 2
while number <= 100:
# Si el número es par, lo imprimimos:
if number % 2 == 0:
print(number)
number += 1
Y aquí tienes la versión dos (más eficiente):
def print_numbers_version_two():
number = 2
while number <= 100:
print(number)
# Incrementamos por 2 directo al siguiente número par:
number += 2
Ambos programas producen exactamente el mismo resultado. Pero la versión uno realiza 100 iteraciones y comprueba la paridad en cada paso. La versión dos solo hace 50 iteraciones y no realiza comprobaciones matemáticas innecesarias. Es el doble de eficiente.
¿Qué es una Estructura de Datos?
Una estructura de datos es la manera física y lógica en la que organizamos, gestionamos y almacenamos los datos en nuestro código. La forma en que eliges organizar tus datos afecta directamente la rapidez con la que tu programa puede operar con ellos.
Para un mismo propósito, puedes usar diferentes estructuras. Por ejemplo, si deseas unir tres palabras:
# Usando variables simples
x = "¡Hola! "
y "¿Cómo estás "
z = "hoy?"
print(x + y + z)
# Usando un Array (o Lista en Python)
array = ["¡Hola! ", "¿Cómo estás ", "hoy?"]
print(array[0] + array[1] + array[2])
Midiendo la velocidad del código
Un error clásico es medir la velocidad de un programa cronometrando los segundos que tarda en completarse. No es la mejor manera, El tiempo de ejecución en segundos varía según:
- El procesador y hardware de la máquina.
- Qué otros programas se están ejecutando en segundo plano.
- El lenguaje de programación y su compilador o intérprete.
Para medir la velocidad de manera científica y objetiva, contamos la cantidad de pasos físicos que requiere un algoritmo para completarse.
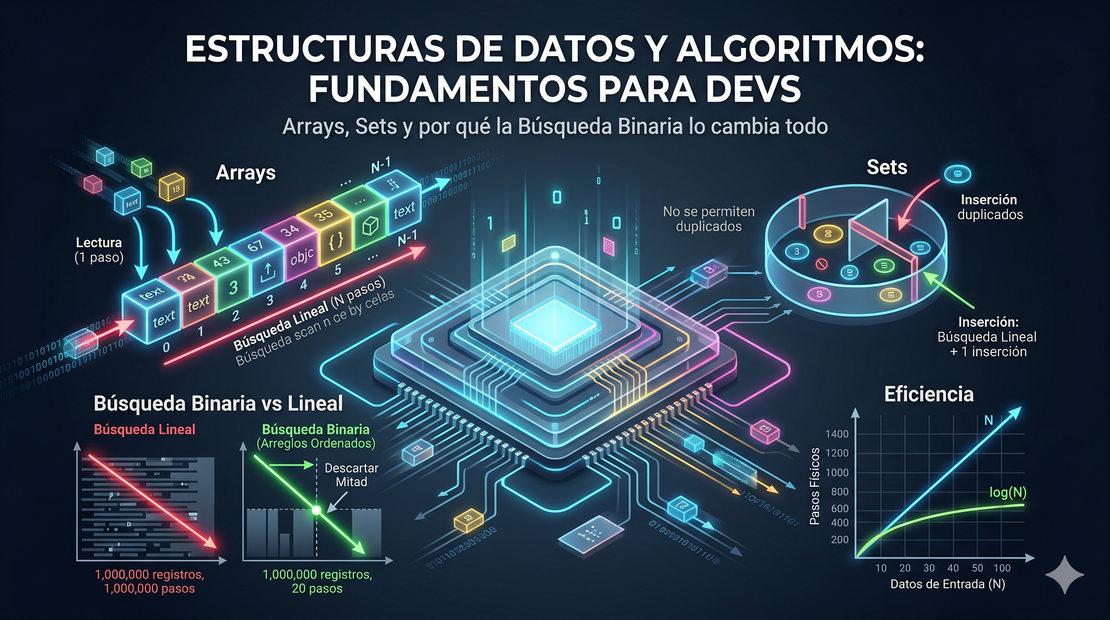
El Array
El Array (o arreglo) es la estructura de datos más básica y el punto de partida de casi todo en computación. Físicamente, un array es un bloque continuo de memoria.
Un array tiene dos características clave:
- Tamaño (Size): El número total de elementos que contiene.
- Índice (Index): La posición numérica de cada celda. En la gran mayoría de lenguajes de programación, empezamos a contar desde 0.
array = ["manzanas", "bananas", "pepinos", "dátiles", "arándanos"]
Podemos representar la memoria de un array así:
flowchart LR
a0["[0] manzanas
Mem: 1000"]
a1["[1] bananas
Mem: 1001"]
a2["[2] pepinos
Mem: 1002"]
a3["[3] dátiles
Mem: 1003"]
a4["[4] arándanos
Mem: 1004"]
a0 --- a1 --- a2 --- a3 --- a4
Las 4 Operaciones Fundamentales en un Array
Para evaluar qué tan eficiente es una estructura de datos, analizamos cuántos pasos le toma realizar las cuatro operaciones básicas:
1. Lectura (Read / Get)
Consiste en obtener el valor que está en un índice específico (por ejemplo, “¿qué hay en la posición 3?”).
- ¿Cómo lo hace la computadora? Al estar guardados en memoria de manera continua, la computadora hace un cálculo matemático simple:
DirecciónInicio + (Índice * TamañoCelda). Va directo a la celda en 1 paso. - Eficiencia: 1 paso (constante).
2. Búsqueda (Search)
Consiste en encontrar el índice de un elemento sabiendo únicamente su valor (por ejemplo, “¿en qué posición están los ‘pepinos’?”).
- ¿Cómo lo hace? La computadora no puede ver el contenido de todo el array a la vez. Debe ir celda por celda, de izquierda a derecha, comprobando si el valor coincide. A esto se le llama Búsqueda Lineal.
- Eficiencia: Si el elemento está al principio, toma 1 paso. Si está al final o no existe, toma N pasos (siendo N el tamaño del array). En el peor de los casos, la eficiencia es de N pasos.
3. Inserción (Insert)
Consiste en agregar un nuevo elemento al array. Aquí tenemos dos escenarios:
- Insertar al final: Es súper sencillo. La computadora simplemente coloca el valor en la siguiente celda libre. Toma 1 paso.
- Insertar al inicio o en medio: ¡Aquí viene el dolor de cabeza! Para meter un valor al inicio (índice 0), primero debemos mover todos los elementos existentes una celda hacia la derecha para abrir espacio.
flowchart TD
subgraph Antes de Insertar
A0["[0] A"] --> A1["[1] B"] --> A2["[2] C"]
end
subgraph Proceso de Desplazamiento
D0["Desplazar C a [3]"] --> D1["Desplazar B a [2]"] --> D2["Desplazar A a [1]"]
end
subgraph Resultado Final
R0["[0] NUEVO"] --> R1["[1] A"] --> R2["[2] B"] --> R3["[3] C"]
end
Si el array tiene tamaño N, insertar al principio toma N desplazamientos + 1 inserción = N + 1 pasos.
4. Eliminación (Delete)
Consiste en borrar un elemento de un índice específico. Al igual que con la inserción, si borramos el elemento del inicio, dejamos un “hueco vacío”. Las reglas de los arrays exigen que no haya espacios vacíos intermedios, por lo que debemos desplazar todos los elementos de la derecha una posición hacia la izquierda.
- Eficiencia: En el peor de los casos (eliminar el primer elemento), toma N - 1 pasos de desplazamiento.
Sets: Cómo una sola regla cambia toda la eficiencia
Un Set (conjunto) es un tipo especial de arreglo con una regla estricta: no se permiten valores duplicados.
Esta pequeña regla de negocio transforma drásticamente la eficiencia de la operación de inserción:
- En un Array común, insertar al final toma 1 paso.
- En un Set, antes de insertar un elemento al final, la computadora debe hacer una búsqueda lineal completa para asegurar que el elemento no exista previamente en el Set.
Por lo tanto, la inserción al final en un Set toma N pasos de búsqueda + 1 paso de inserción = N + 1 pasos.
Note
Aunque los Sets protegen la integridad de tus datos previniendo duplicados, debes tener en cuenta que su inserción es mucho más lenta en arreglos de gran tamaño.
Arreglos Ordenados
Un Arreglo Ordenado es un array cuyos valores se mantienen de forma ascendente o descendente de forma obligatoria.
Inserción en Arreglos Ordenados
Para insertar un valor en un arreglo ordenado (por ejemplo, meter el número 4 en [1, 3, 5, 8]), no podemos simplemente agregarlo al final. Debemos:
- Buscar el lugar exacto donde corresponde el elemento para mantener el orden (después del
3y antes del5). - Desplazar los elementos mayores hacia la derecha (
5y8). - Insertar el nuevo valor.
Esto hace que la inserción sea ligeramente más costosa en pasos que en un array normal, pero abre la puerta a un algoritmo de búsqueda revolucionario.
Búsqueda Binaria
Si tu arreglo no está ordenado, la única forma de buscar es la búsqueda lineal (celda por celda), lo que toma hasta N pasos.
Pero si tu arreglo sí está ordenado, puedes usar la Búsqueda Binaria. Este algoritmo consiste en:
- Ir directo al elemento del medio del arreglo.
- Si el valor buscado es menor, descartas toda la mitad derecha.
- Si es mayor, descartas toda la mitad izquierda.
- Repites el proceso en la mitad restante hasta encontrarlo o quedarte sin elementos.
flowchart TD
Start["Buscar 11 en [2, 4, 6, 8, 11, 14, 18, 22]"] --> Step1["Valor central: 8 (índice 3)"]
Step1 --> Check{"¿Es 11 == 8?"}
Check -- No, es mayor --> DescartarIzq["Descartar [2, 4, 6, 8]"]
DescartarIzq --> SubSearch["Buscar en [11, 14, 18, 22]"]
SubSearch --> Step2["Valor central: 14 (índice 5)"]
Step2 --> Check2{"¿Es 11 == 14?"}
Check2 -- No, es menor --> DescartarDer["Descartar [14, 18, 22]"]
DescartarDer --> Final["Buscar en [11] -> ¡Encontrado! 🎉"]
Búsqueda Binaria vs. Búsqueda Lineal
| Tamaño del Arreglo (N) | Pasos Máximos (Lineal) | Pasos Máximos (Binaria) |
|---|---|---|
| 8 | 8 | 3 |
| 100 | 100 | 7 |
| 10,000 | 10,000 | 14 |
| 1,000,000 | 1,000,000 | 20 |
La diferencia es notable. Buscar en una base de datos de un millón de registros toma un millón de pasos con búsqueda lineal, pero solo 20 pasos usando búsqueda binaria. Por eso, elegir el algoritmo correcto de acuerdo a la estructura de tus datos marca toda la diferencia del mundo.
En el siguiente post, aprenderemos la forma matemática formal en la que los desarrolladores expresamos estas diferencias de eficiencia: la Notación Big O, y cómo usarla para analizar nuestros primeros algoritmos de ordenamiento. ¡No te lo pierdas! 🚀


