Sistemas Agénticos: El Espectro de Autonomía y Desarrollo Responsable
- Dacadev
- Inteligencia artificial generativa
- 18 de mayo de 2026
Tabla de Contenido
Cuando empezamos a programar con LLMs (Large Language Models), a menudo nos quedamos en la fase de “pregunta-respuesta”. Le envías un prompt al modelo y este te devuelve una respuesta inmediata. Pero el verdadero poder de la Inteligencia Artificial (IA) surge cuando le damos libertad al modelo para actuar por sí mismo, tomar decisiones y corregir su camino.
Aquí es donde entramos al tema de los Sistemas Agénticos. Te has preguntado:
- ¿cuánta libertad debería tener realmente una IA?
- ¿Cómo nos aseguramos de que no tome acciones destructivas?
- ¿Cómo medimos si está haciendo bien su trabajo?
Note
En este artículo aprenderás qué define a un sistema agéntico, exploraremos el espectro de autonomía desde un simple prompt hasta agentes 100% autónomos, y analizaremos las mejores prácticas de desarrollo responsable y evaluación de sistemas agénticos. 🚀
¿Qué es un Sistema Agéntico?
Un sistema se considera agéntico en la medida en que el LLM tiene el control para tomar decisiones, elegir herramientas y definir los pasos a seguir para alcanzar un objetivo.
A diferencia de un software tradicional basado puramente en reglas rígidas y flujos de control fijos (if/else), un sistema agéntico exhibe un comportamiento orientado a metas (goal-directed behavior). Nosotros le decimos el qué (el objetivo final) y el agente decide el cómo (el plan de ejecución).
No obstante, la autonomía no es un interruptor binario de “todo o nada”. Existe un amplio espectro de control que podemos otorgar a nuestros agentes, dependiendo de la criticidad de la tarea y de los límites que queramos establecer.
El Espectro de Autonomía
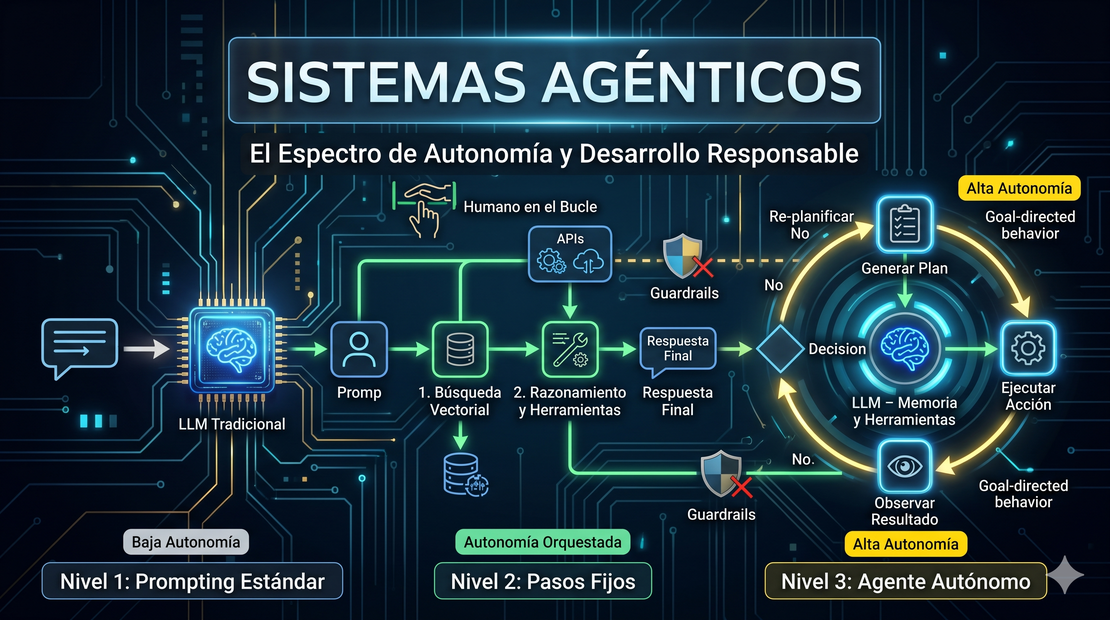
Dependiendo del diseño del sistema, un agente de IA puede tener diferentes grados de libertad. En la práctica, podemos clasificar la autonomía en tres grandes niveles:
Nivel 1: Prompting Estándar (Baja Autonomía)
Es el nivel básico. El usuario envía un prompt, el LLM procesa la solicitud utilizando únicamente su conocimiento interno y genera una respuesta directa. No hay uso de herramientas externas ni toma de decisiones sobre el flujo de ejecución. El control es 100% del usuario.
flowchart LR P[User Prompt] --> LLM[🧠 LLM Tradicional] --> Ans1[Respuesta Directa]
Nivel 2: Pasos Fijos (Autonomía Orquestada / RAG)
En este nivel, el agente está integrado dentro de un flujo de trabajo predefinido (orquestado). Por ejemplo, un sistema RAG (Generación Aumentada por Recuperación) primero ejecuta una búsqueda vectorial en una base de datos de manera obligatoria (Paso 1) y luego le pasa ese contexto al LLM para que redacte la respuesta final (Paso 2). El modelo tiene cierta autonomía para elegir herramientas locales o resumir la información, pero no puede alterar el flujo global de los pasos.
flowchart LR P2[User Prompt] --> S1[🔍 Paso 1: Búsqueda Vectorial] S1 --> S2[🧠 Paso 2: Razonamiento y Herramientas] S2 --> Ans2[Respuesta Final]
Nivel 3: Agente Autónomo (Alta Autonomía)
Aquí el agente tiene total libertad dentro de un bucle de ejecución interactivo. El LLM recibe una meta, genera un plan inicial, ejecuta una acción (como llamar a una API o ejecutar código), observa el resultado del entorno, actualiza su plan y decide de forma autónoma si ha logrado cumplir el objetivo o si necesita seguir iterando.
flowchart TD
P3[User Prompt] --> RLLM[🧠 LLM - Memoria y Herramientas]
RLLM --> Plan[📋 Generar Plan]
Plan --> Action[⚙️ Ejecutar Acción]
Action --> Observe[👁️ Observar Resultado]
Observe --> Decision{¿Meta cumplida?}
Decision -->|No: Re-planificar| Update[🔄 Actualizar Plan]
Update --> RLLM
Decision -->|Sí| Ans3[Respuesta Final]
Casos de Uso del Mundo Real
Los sistemas agénticos ya están transformando múltiples industrias. Algunos de los ejemplos más destacados son:
- Coding Agents (Agentes de Programación): Herramientas que no solo sugieren código, sino que pueden leer repositorios enteros, escribir pruebas unitarias, ejecutar programas en entornos de prueba seguros (sandboxes) y depurar errores por sí mismos hasta que el código funcione.
- Búsqueda Profunda (DeepSearch): Agentes de investigación que realizan búsquedas web iterativas, cruzando múltiples fuentes de información, validando datos contradictorios y redactando reportes completos de manera autónoma.
- Automatización de Procesos de Negocio: Agentes capaces de interactuar con software de facturación, responder correos electrónicos de clientes resolviendo problemas complejos y actualizar bases de datos sin intervención humana constante.
Desarrollo y Uso Responsable de Agentes IA
Darle autonomía a un agente digital conlleva grandes riesgos. Si le permites a un agente ejecutar comandos en tu terminal o enviar correos a tus clientes, un pequeño error de razonamiento o una alucinación podría causar pérdidas de información o daños reputacionales.
Por ello, el desarrollo ético y seguro de agentes requiere la implementación de tres pilares fundamentales:
1. Humano en el Bucle (Human-in-the-Loop)
Consiste en diseñar puntos de control donde el agente deba detener su ejecución y solicitar la aprobación explícita de un ser humano antes de realizar acciones críticas o irreversibles.
Tip
Regla de oro: Si una acción del agente tiene efectos directos en el mundo físico o digital real (ej. realizar un pago, enviar un email a un cliente, o borrar un archivo), siempre debes implementar una aprobación humana previa. 🚀
2. Guardrails (Límites y Barreras Técnicas)
Los guardrails son capas de software que rodean al agente y restringen lo que puede y no puede hacer. Algunas estrategias eficaces incluyen:
- Validación Estricta de Entradas y Salidas: Analizar y limpiar los prompts enviados al LLM y las llamadas a herramientas generadas por este.
- Presupuesto de Tokens y Pasos: Limitar el número de iteraciones máximas del bucle autónomo para evitar bucles infinitos muy costosos.
- Entornos Seguros (Sandboxing): Ejecutar cualquier herramienta de código o comando del sistema dentro de contenedores aislados (como Docker) para proteger la máquina anfitriona.
3. Mitigación de Desinformación y Sesgos
Los agentes pueden propagar información falsa rápidamente si no se controlan sus fuentes de datos. Es vital dotar al agente de capacidades de contraste y verificación de datos cuando trabaja en entornos abiertos como internet, además de que de por si un LLM puede alucinar, dando respuestas que suenan plausibles pero son completamente inventadas.
Evaluando Sistemas Agénticos: Un Desafío Complejo
Si evaluar un LLM tradicional (que solo produce texto) ya es difícil, evaluar un agente es considerablemente más complejo. Un agente interactúa con su entorno, ejecuta múltiples pasos lógicos y toma decisiones secuenciales donde cada acción influye en el siguiente estado del sistema.
Al evaluar sistemas agénticos, no podemos limitarnos a verificar si el texto final “se lee bien”. Debemos evaluar el sistema completo bajo múltiples dimensiones:
| Dimensión de Evaluación | Qué mide | Cómo se evalúa |
|---|---|---|
| Tasa de Éxito de la Tarea | Si el agente logró resolver la meta propuesta correctamente. | Pruebas de integración automatizadas con metas claras y verificables. |
| Eficiencia de la Trayectoria | El número de pasos y tokens utilizados. Un agente que resuelve el problema en 3 pasos es mejor que uno que toma 20. | Análisis de logs de ejecución y costos asociados. |
| Alineación y Cumplimiento | Si el agente respetó las políticas de seguridad y las barreras técnicas durante su ejecución. | Inyección de prompts maliciosos de prueba (Red Teaming). |
| Resiliencia ante Errores | Cómo reacciona el agente cuando una herramienta falla o una API devuelve un código de error. | Simulación de caídas de servicios y análisis de la capacidad de replanificación del agente. |
La evaluación constante es la única forma de garantizar que el agente sea seguro, confiable y verdaderamente útil antes de desplegarlo en un entorno de producción crítico.
Conclusión
La autonomía de los agentes de IA abre un mundo lleno de posibilidades, pero también exige un alto nivel de responsabilidad de nuestra parte como desarrolladores. Al comprender el espectro de autonomía, diseñar e implementar guardrails técnicos sólidos e implementar metodologías de evaluación robustas, podemos construir herramientas agénticas que asombren a nuestros usuarios a la vez que se mantienen totalmente seguras.
En la próxima entrega de esta serie, exploraremos cómo podemos escalar estos sistemas haciendo que múltiples agentes con especialidades únicas colaboren entre sí. ¡Nos vemos en el próximo artículo!